- 課題: 「Custom RAG」は語られすぎているが、ほとんど証明されない。多くはLangChainデモ止まりで、チャンキングもハイブリッド検索もevalもない。
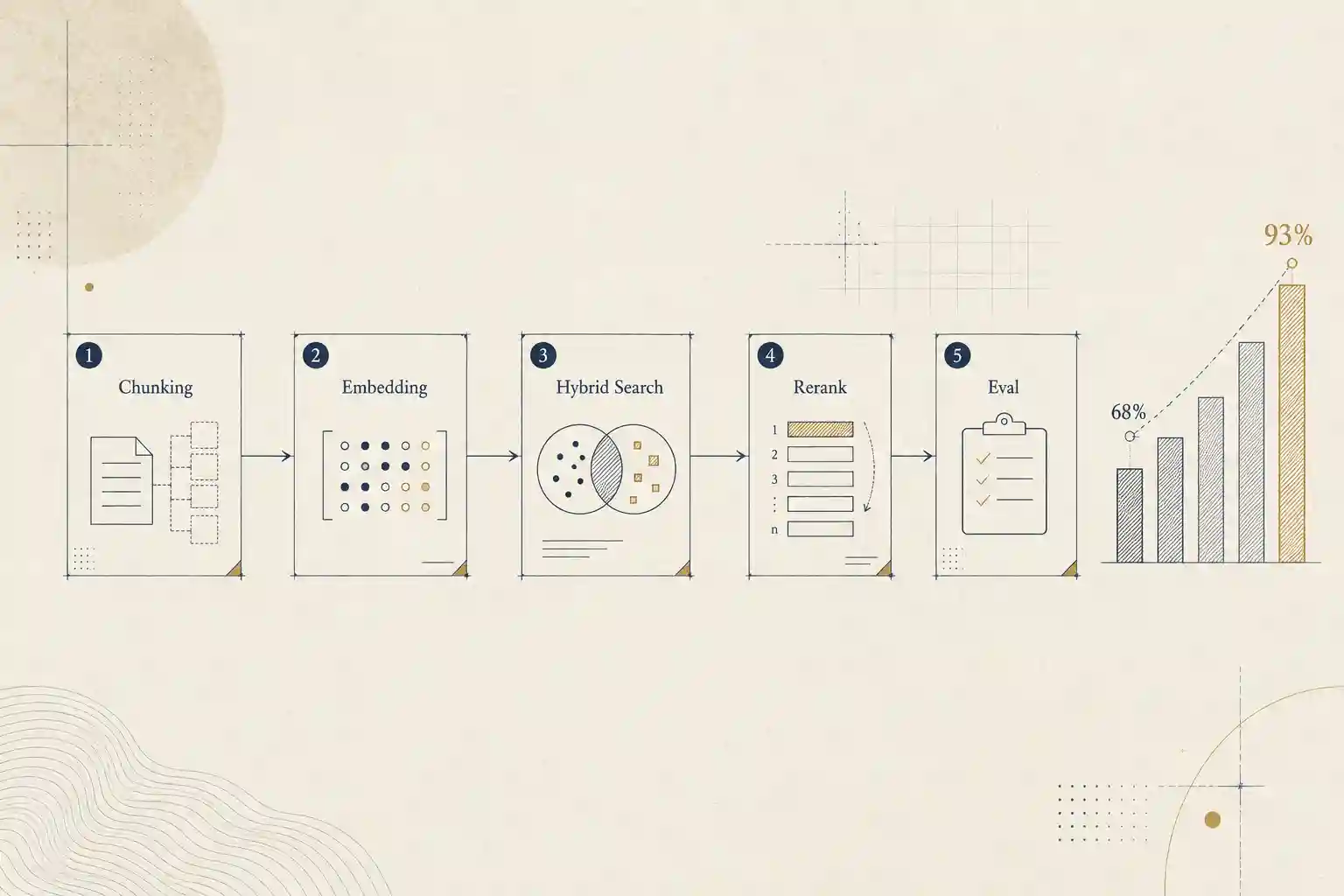
- 解決策: 5つの判断からなるパイプライン(チャンキング→埋め込み→ハイブリッド検索→リランキング→eval)。勝敗を分けるのはモデルではなく検索(retrieval)である。
- 結果: structure-awareチャンキング、BM25、リランカーを加えることで、同一のゴールデンセットでRecall@5が68%から93%へ。推測ではなく実測値。
結論から: 本当に「動く」Custom RAG は、モデル選定の段階で決まるのではなく、検索(retrieval)パイプラインで決まります。文書をどうチャンキングするか、どのモデルで埋め込むか、ハイブリッド検索(ベクトル+BM25)を行うか、リランクするか、そして最も重要なのは——何で測定するか。市場に出回る「RAG」の多くは、これらの層を一切持たないLangChainデモ止まりです。本稿では、私が日越多言語RAGで実際に使っているパイプラインを、数値の入ったeval表とともに開けてみせます。
TL;DR(エグゼクティブサマリー)
- 課題: 「Custom RAG」は乱用された言葉です。LLMをベクトルストアにつなぐ20行のデモは本番RAGではありません——表、契約コード、言語をまたぐ質問に出会った瞬間に崩壊します。
- 解決策: 5段階のパイプライン——structure-awareチャンキング → 多言語埋め込み → ハイブリッド検索 → リランキング → 測定可能なeval。各段階が固有の検索失敗を一つずつ塞ぎます。
- 結果: 同一のゴールデンセットで、各技術を加えるごとにRecall@5は 68%→93%、faithfulnessは 0.74→0.91 へ。印象ではなく実測値です。
「RAG」とは実際には何か——そしてなぜデモは誤解を招くのか
運用の視点では、RAGは「あなたのデータにLLMを差し込む」ことではありません。RAGは末尾に生成層を付けた情報検索(information retrieval)の問題です。品質の90%は検索にあります——デモが「地味だから」と飛ばす部分です。
デモが誤解を招くのは、きれいな5つの質問、整ったドキュメント、単一言語で試されるからです。本番は違います。スキャンPDF、条項の表、ベトナム語と日本語が混在するクエリ、誤字を打つユーザー、そして正解が**「該当する情報はありません」**である質問。これらを想定していないパイプラインは捏造します——捏造を防ぐアーキテクチャ層についてはハルシネーションを防ぐCustom RAG:3層アーキテクチャで詳述しました。本稿はその一層下、その下で動く検索エンジンそのものに踏み込みます。
5段階パイプライン——各段階が塞ぐ失敗
第1段階 — チャンキング:多くのシステムが静かに死ぬ場所
既定のやり方——512トークン固定+オーバーラップ——は、最も精度を要する文書をまさに破壊します。条項の表が行の途中で切られれば文脈を失い、800トークンの条項が二つに裂かれれば、どのチャンクにも完全な意味が残りません。
私が使うのはstructure-awareチャンキングです。固定トークン数ではなく、文書の意味的境界——見出し、条・項、表のセル境界——に沿って切ります。狙いは、各チャンクがそれ自体で完結する意味単位であること。通常300〜500トークン、境界の文脈を保つためオーバーラップを約15%。表については行構造を保持(row-aware)し、各行に列見出しを付与します。ユーザーは孤立したセルではなく、行で質問するからです。
チームに必ず言う原則:インデックスに入ったゴミは、どんなリランカーでも救えません。チャンキングは最も安価な層でありながら、システム全体の品質の上限を決めます。
第2段階 — 埋め込み:単一言語モデルは日越市場における罠
ベトナム語の質問が、日本語で書かれた条項を検索する必要がある——これは仮定ではなく実際の状況です。単一言語の埋め込みモデル(あるいは英語に最適化されたモデル)はここで脱落します。私はviとjaを一つの共有ベクトル空間に置く多言語埋め込みモデルを選び、言語横断検索(cross-lingual retrieval)が機能するようにします。
見落とされがちな点:専門用語です。保険商品名、業務コード、社内略語——汎用埋め込みはこれらを誤って解釈します。私はグロッサリーを保持し、これらの実体をインデックス側とクエリ側の両方で処理して、意味的に「誤訳」されないようにします。
第3段階 — ハイブリッド検索:ベクトルは意味に強く、完全一致に弱い
これがデモRAGと本番RAGを分ける段階です。ベクトル検索は意味で探します——言い換えられた質問には抜群です。しかしユーザーが契約番号 HD-2024-887 や条項コード 第12条を打つとき、意味はほぼ無力です。必要なのは完全なキーワード一致です。
解決策は、二つのリトリーバーを並列に走らせること——dense(ベクトル)+ sparse(BM25)——そしてReciprocal Rank Fusionで統合します。ベクトルが言い換えの質問を、BM25が識別子と希少語を捕捉します。この段階だけで、パイプライン全体で最大のリコール上昇になることが多いです。
第4段階 — リランキング:「十分に関連」と「まさに正しい」を分ける
リトリーバーはtop-kを高速に返しますが粗い。クロスエンコーダのリランカーが(質問, チャンク)の各ペアを読み直して真の関連度を採点し、粗いtop-50を精密なtop-5へ絞ります。違いはこうです。リトリーバーは質問とチャンクを独立に埋め込みますが、リランカーは両者を一緒に見るため、コサイン類似度が見落とすニュアンスを捉えます。
代償はレイテンシです——リランクは時間を要します。だから私は粗いtop-k(50)だけをリランクし、コーパス全体はリランクしません。他のあらゆるアーキテクチャ判断と同じく、案件ごとに調整するトレードオフです。
第5段階 — eval:測定できないなら、それを所有していない
これは、RAGを運用する人とRAGをデモする人を分ける段階です。evalがなければ、あらゆる「改善」は感覚にすぎず、ある変更がシステムを良くしたのか悪くしたのか決して分かりません。
私はゴールデンセットを構築します。数百組の(質問 → 正しい出典文書 → 期待される回答)で、正解が*「該当する情報はありません」*である質問も含めます。そして責任を分離する指標で測定します。
- Recall@k — 正しい文書はtop-kに含まれているか?(検索段階のみを測る)
- Faithfulness/Groundedness — 回答は検索結果に根拠づけられ、何も捏造していないか?(生成段階のみを測る)
- 正しい「分かりません」率 — 出典がないとき、システムは推測せず「該当情報なし」と言えるか?
eval表:各技術を積み上げる
同一のゴールデンセットに対して各段階を有効化したときに私が見る結果の形です(単一案件ではなく、実務パターンから示した参考値):
| 構成 | Recall@5 | Faithfulness | 正しい「分かりません」 |
|---|---|---|---|
| Naive(固定チャンク+ベクトルのみ) | 68% | 0.74 | 31% |
| + Structure-awareチャンキング | 79% | 0.81 | 44% |
| + ハイブリッド検索(BM25) | 88% | 0.85 | 61% |
| + リランカー | 93% | 0.91 | 78% |
重要なのは最終的な数値ではなく、その経路です。各段階が固有の失敗を塞ぎ、どの段階が金を払う価値があるかは、この表があって初めて分かります。何で測定するかを言えないままRAG案件を見積もるチームは、たいてい本番での誤答に責任を負ったことのないチームです。
このRAGは何で「ない」のか——誤って買わないために
期待値について率直に言います。このパイプラインは、SMEから中堅企業規模における企業文書セット(ナレッジベース、契約、社内手順)に対する精度に最適化されています。以下ではありません:
- 数十億ベクトルをリアルタイム処理する基盤——それは別のインフラ問題であり、専任のデータエンジニアリングチームを要します。
- 「絶対に誤り0%」の約束——どんなシステムもそれは約束できません。あなたが買うのは、制御可能で測定可能な誤差です。
- 出典データの品質を飛ばす言い訳——出典文書が乱れていれば結果も乱れます。それはモデルを語る前にやるべき仕事です。
道具を選ぶ前に問題を正しく分類する思考については、ビジネス課題を解決するシステム思考で詳述しました。
誤答に実際のコストが伴うプロセスにRAGを導入することを検討していて、システムをデモするだけでなく測定する人と組みたいなら、AI自動化の対応領域をご覧いただくか、実際のプロジェクトストーリーを読むか、システムの課題を送るからご相談ください。
Nguyen Chau
Delivery Manager / System Architect
日越市場におけるシステムの設計・運用で14年の経験
よくある質問
RAGシステムを評価する上で最も重要な指標は何か?
モデルでもベクトルDBでもなく、**出典データの正規化**(第1段階)と**evalセットの構築**(第5段階)です。これらは「地味」でありながら、システムの生死を決める部分です。モデルAPI呼び出しの費用しか見積もらないチームは、たいてい誤差に実際の代償が伴う環境で本物のRAGを運用したことのないチームです。
純粋なベクトル検索ではなくハイブリッド検索が必要になるのはいつか?
正しい答えは「規模による」であって「いま流行りのもの」ではありません。SME規模なら、pgvectorを備えたPostgresで十分なことが多く、運用も簡単です。ベクトル数とレイテンシ要件が増えて初めて、専用ベクトルDB(Qdrant、Milvusなど)が追加の運用コストに見合います。規模を知る前にベクトルDBを選ぶのは、本末転倒です。