- Problem: "Custom RAG" is overclaimed but rarely proven — most of it stops at a LangChain demo, with no chunking, hybrid search, or eval.
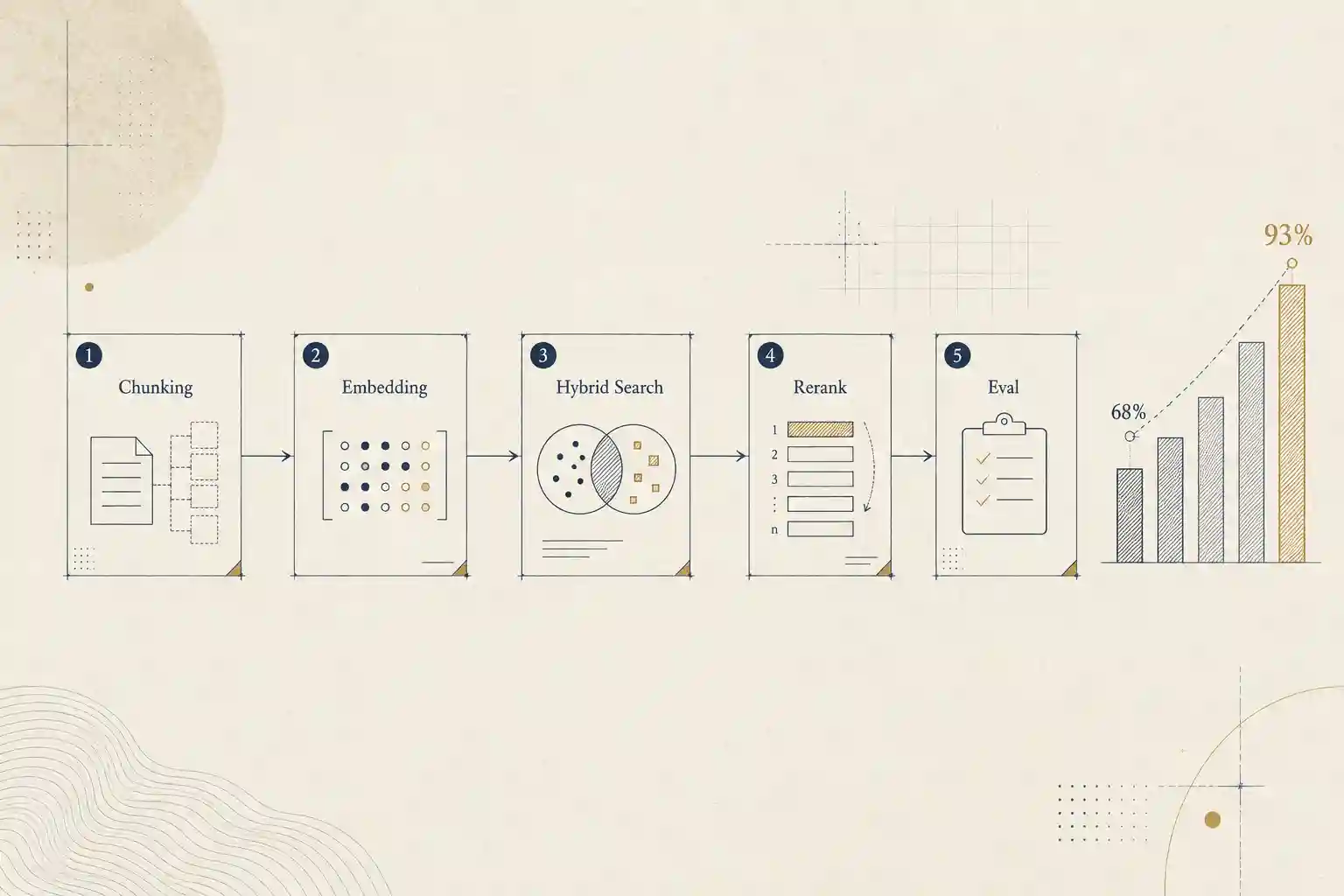
- Solution: A 5-decision pipeline (chunking → embedding → hybrid search → reranking → eval) where retrieval — not the model — is where you win or lose.
- Result: An eval table showing Recall@5 going from 68% (naive) to 93% after adding structure-aware chunking, BM25, and a reranker — measured, not guessed.
Short answer: A Custom RAG that "works" is not decided at the model-selection step — it's decided in the retrieval pipeline: how you chunk documents, which model you embed with, whether you run hybrid search (vector + BM25), whether you rerank, and most importantly — what you measure it with. Most "RAG" on the market stops at a LangChain demo with none of these layers. This post opens up the real pipeline I use for multilingual Vietnam–Japan RAG, with an eval table that has numbers.
TL;DR (Executive Summary)
- Problem: "Custom RAG" is an abused phrase. A 20-line demo wiring an LLM to a vector store is not production RAG — it breaks the moment it meets tables, contract codes, or cross-lingual questions.
- Solution: A 5-stage pipeline — structure-aware chunking → multilingual embedding → hybrid search → reranking → measurable eval. Each stage closes a distinct class of retrieval failure.
- Result: On the same golden set, Recall@5 moves from 68% → 93% and faithfulness from 0.74 → 0.91 as each technique is added. These are measured numbers, not impressions.
What "RAG" actually is — and why demos mislead
From an operational view, RAG is not "plug an LLM into your data." RAG is an information-retrieval problem with a generation layer bolted on at the end. 90% of the quality lives in retrieval — the part demos skip because it isn't sexy.
Demos mislead because they're tested on 5 pretty questions, clean documents, one language. Production is different: scanned PDFs, clause tables, queries mixing Vietnamese and Japanese, users with typos, and questions where the correct answer is "no information available." A pipeline not designed for those will fabricate — and I covered the architecture layer that prevents fabrication in Custom RAG against hallucination: a 3-tier architecture. This post goes one layer deeper: the retrieval engine underneath it.
The 5-stage pipeline — and the failure each stage closes
Stage 1 — Chunking: where most systems die quietly
The default approach — fixed 512-token cuts with overlap — destroys exactly the documents that need the most precision. A clause table cut mid-row loses its context; an 800-token clause split in half leaves no chunk with full meaning.
What I use is structure-aware chunking: cutting along the document's semantic boundaries — headings, articles/clauses, table-cell boundaries — not along a rigid token count. The goal: each chunk is a self-contained semantic unit, usually 300–500 tokens, with ~15% overlap to preserve boundary context. For tables I keep the row structure (row-aware) and attach column headers to each row, because users ask by row, not by isolated cell.
The rule I always repeat to the team: garbage that enters the index can't be saved by any reranker. Chunking is the cheapest layer but it sets the quality ceiling of the whole system.
Stage 2 — Embedding: a monolingual model is a trap in the Vietnam–Japan market
A Vietnamese question needs to retrieve a clause written in Japanese — this is a real situation, not a hypothetical. A monolingual embedding model (or one tuned for English) fails right here. I pick a multilingual embedding model that puts vi and ja in one shared vector space, so cross-lingual retrieval actually works.
A detail people skip: domain terminology. Insurance product names, business codes, internal abbreviations — generic embeddings misread them. I keep a glossary and handle these entities on both the index and the query side so they don't get semantically "mistranslated."
Stage 3 — Hybrid search: vector is strong on semantics, weak on exact match
This is the stage that separates demo RAG from production RAG. Vector search finds by meaning — excellent for paraphrased questions. But when a user types a contract number HD-2024-887 or a clause code 第12条, semantics is nearly useless; you need exact keyword match.
The solution is running two retrievers in parallel — dense (vector) + sparse (BM25) — then fusing them with Reciprocal Rank Fusion. Vector catches paraphrased questions, BM25 catches identifiers and rare terms. This stage alone is usually the biggest single recall jump in the whole pipeline.
Stage 4 — Reranking: separating "relevant enough" from "exactly right"
The retriever returns top-k fast but coarse. A cross-encoder reranker re-reads each (question, chunk) pair, scores true relevance, and narrows a coarse top-50 to a precise top-5. The difference: the retriever embeds question and chunk independently; the reranker looks at them together, so it catches nuance cosine similarity misses.
The cost is latency — reranking takes time. So I only rerank the coarse top-k (50), never the whole corpus. It's a trade-off I tune per project, like every other architectural decision.
Stage 5 — Eval: if you can't measure it, you don't own it
This is the stage that separates someone who operates RAG from someone who demos it. Without eval, every "improvement" is a feeling, and you never know whether a change made the system better or worse.
I build a golden set: a few hundred pairs of (question → correct source document → expected answer), including questions where the correct answer is "no information available." Then I measure with metrics that separate responsibility:
- Recall@k — is the correct document in the top-k retrieved? (measures the retrieval stage alone)
- Faithfulness / Groundedness — does the answer stay grounded in what was retrieved, with nothing invented? (measures the generation stage alone)
- Correct "I don't know" rate — when there's no source, does the system actually say "no information" instead of guessing?
The eval table: stacking each technique
This is the shape of the result I see as each stage is turned on against the same golden set (illustrative numbers from real-world patterns, not a single project):
| Configuration | Recall@5 | Faithfulness | Correct "don't know" |
|---|---|---|---|
| Naive (fixed chunk + vector only) | 68% | 0.74 | 31% |
| + Structure-aware chunking | 79% | 0.81 | 44% |
| + Hybrid search (BM25) | 88% | 0.85 | 61% |
| + Reranker | 93% | 0.91 | 78% |
What matters isn't the final number, it's the path: each stage closes a distinct class of failure, and you only know which stage is worth paying for when you have this table. A team quoting a RAG project that can't tell you what they'll measure with is usually a team that has never been accountable for a wrong answer in production.
What this RAG is NOT — so you don't buy the wrong thing
Let me be direct about expectations. This pipeline is optimized for accuracy over an enterprise document set (knowledge bases, contracts, internal procedures) at SME to mid-enterprise scale. It is not:
- A platform processing billions of vectors in real time — that's a different infrastructure problem needing a dedicated data-engineering team.
- A promise of "0% error, ever" — no system can promise that; what you buy is error that is controllable and measurable.
- An excuse to skip source-data quality — messy source documents mean messy results, and that's work to do before you talk about models.
The thinking of classifying the problem correctly before choosing the tool, I covered in depth in Systems Thinking for solving business problems.
If you're considering putting RAG into a process where a wrong answer has a real cost — and you want to work with someone who measures their system rather than just demos it — you can see more on AI Automation capabilities, read real project stories, or send a systems problem to discuss.
Nguyen Phuc Nguyen Chau
Delivery Manager / System Architect
14 years architecting and operating systems for the Vietnam–Japan market
Frequently Asked Questions
What is the single most important metric for evaluating a RAG system?
Retrieval recall (Recall@k) and faithfulness/groundedness — not "the answer sounds good." Recall@k measures whether the correct document is in the top-k retrieved; faithfulness measures whether the answer stays grounded in what was retrieved. If retrieval is wrong, everything downstream is wrong.
When do you need hybrid search instead of pure vector search?
When queries contain exact identifiers — contract numbers, clause codes, product codes. Vector search is strong on semantics but weak on exact match; adding BM25 (sparse) and fusing the results catches both kinds of query.
Should I fine-tune a model or build RAG for enterprise data?
In most enterprise cases, RAG wins. Enterprise data changes constantly — updated clauses, new documents — and re-fine-tuning each time is both expensive and hard to trace to source. RAG updates knowledge by updating the index, and always cites its source, which is a hard requirement when compliance is involved.
Which vector DB should I use?
The correct answer is "it depends on scale," not "whichever is hottest." At SME scale, a Postgres with pgvector is usually enough and simple to operate. As vector count and latency requirements grow, a dedicated vector DB (Qdrant, Milvus...) starts to earn its extra operational cost. Choosing a vector DB before you know the scale is putting the cart before the horse.
Where is the most expensive part of building real RAG?
Not the model or the vector DB — it's **normalizing the source data** (Stage 1) and **building the eval set** (Stage 5). These are the "unsexy" parts that decide whether the system lives or dies. A team quoting only the cost of model API calls is usually a team that has never operated real RAG in an environment where errors have a real price.