- Bài toán: "Custom RAG" bị nói quá nhiều nhưng hiếm khi được chứng minh — phần lớn dừng ở demo LangChain, không có chunking, hybrid search hay eval.
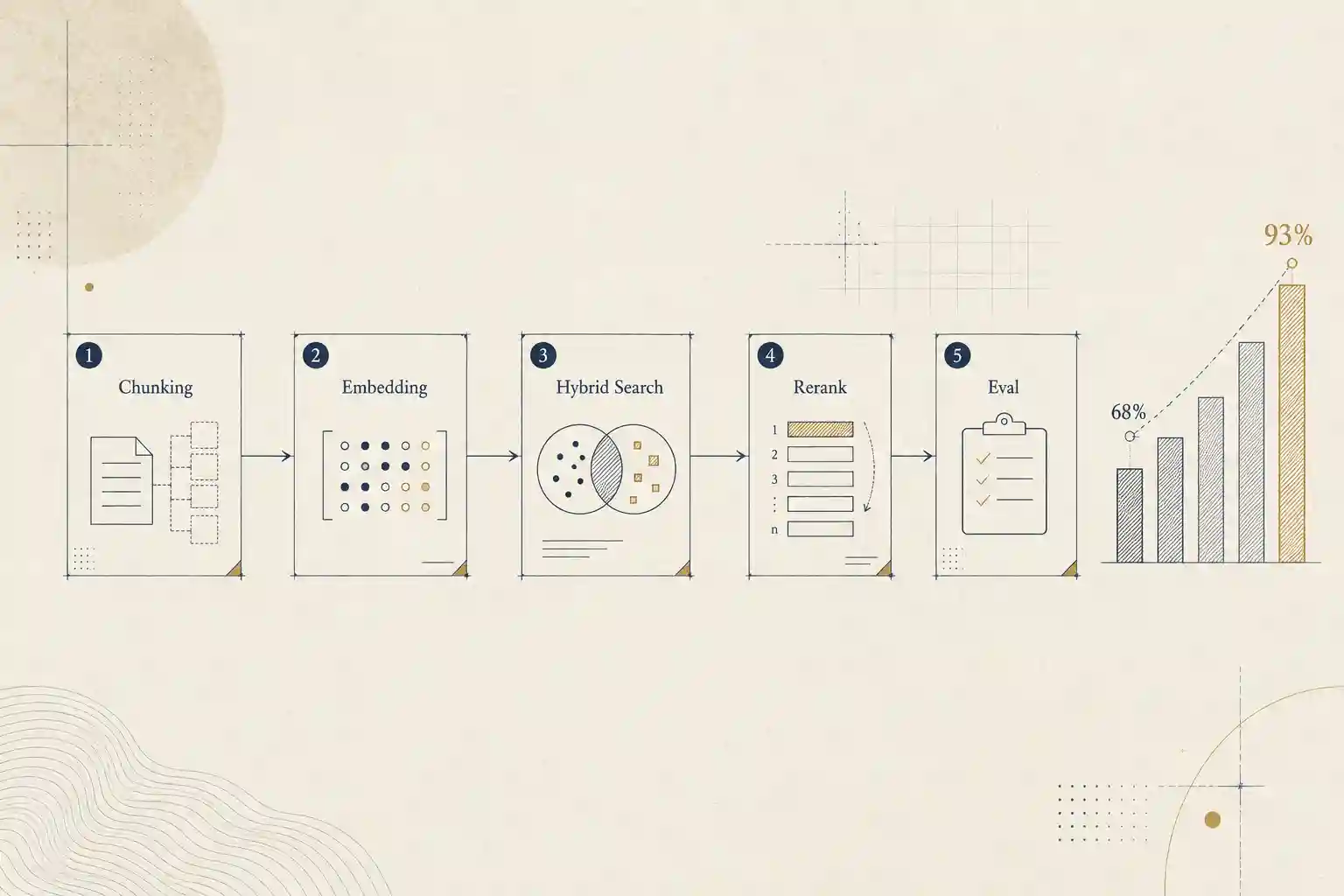
- Giải pháp: Một pipeline 5 quyết định (chunking → embedding → hybrid search → reranking → eval), trong đó retrieval mới là chỗ thắng/thua chứ không phải model.
- Kết quả: Bảng eval cho thấy Recall@5 đi từ 68% (naive) lên 93% sau khi thêm structure-aware chunking, BM25 và reranker — đo được, không cảm tính.
Câu trả lời ngắn: Một Custom RAG "chạy được" không được quyết định ở bước chọn model, mà ở retrieval pipeline: bạn chunk tài liệu thế nào, embed bằng model nào, có hybrid search (vector + BM25) không, có rerank không, và quan trọng nhất — bạn đo nó bằng gì. Phần lớn "RAG" ngoài thị trường dừng ở demo LangChain không có lớp nào trong số này. Bài này mở nắp pipeline thật mà tôi dùng cho RAG đa ngôn ngữ Việt–Nhật, kèm bảng eval có số.
TL;DR (Executive Summary)
- Bài toán: "Custom RAG" là cụm từ bị lạm dụng. Một demo nối LLM với vector store trong 20 dòng code không phải RAG production — nó vỡ ngay khi gặp bảng biểu, mã hợp đồng, hay câu hỏi đa ngôn ngữ.
- Giải pháp: Một pipeline 5 tầng — structure-aware chunking → embedding đa ngôn ngữ → hybrid search → reranking → eval đo được. Mỗi tầng đóng một loại lỗi retrieval riêng.
- Kết quả: Trên cùng một bộ câu hỏi vàng (golden set), Recall@5 đi từ 68% → 93% và faithfulness từ 0.74 → 0.91 khi cộng dồn từng kỹ thuật. Đây là con số đo được, không phải cảm nhận.
"RAG" thực ra là gì — và vì sao demo lại đánh lừa?
Dưới góc nhìn vận hành, RAG không phải "cắm LLM vào dữ liệu của bạn". RAG là một bài toán information retrieval có thêm tầng sinh ngôn ngữ ở cuối. 90% chất lượng nằm ở phần retrieval — phần mà demo thường bỏ qua vì nó "không sexy".
Demo đánh lừa vì nó được thử trên 5 câu hỏi đẹp, tài liệu sạch, một ngôn ngữ. Production thì khác: PDF scan, bảng điều khoản, truy vấn lẫn tiếng Việt và tiếng Nhật, người dùng gõ sai chính tả, và câu hỏi mà đáp án đúng là "không có thông tin". Một pipeline không được thiết kế cho những thứ đó sẽ bịa — và tôi đã viết kỹ về lớp kiến trúc chống bịa trong bài Custom RAG chống ảo giác: kiến trúc 3 lớp. Bài này đi xuống một tầng sâu hơn: chính cái retrieval engine bên dưới.
Pipeline 5 tầng — và lỗi mà mỗi tầng đóng lại
Tầng 1 — Chunking: chỗ hầu hết hệ thống chết âm thầm
Cách mặc định — cắt cố định 512 token với overlap — phá nát đúng những tài liệu cần chính xác nhất. Một bảng điều khoản bị cắt giữa dòng thì câu trả lời mất ngữ cảnh; một điều khoản dài 800 token bị xé làm đôi thì không chunk nào còn đủ nghĩa.
Cái tôi dùng là structure-aware chunking: cắt theo ranh giới ngữ nghĩa của tài liệu — heading, điều/khoản, ranh giới ô bảng — chứ không theo số token cứng. Mục tiêu: mỗi chunk là một đơn vị ngữ nghĩa tự đứng được, thường 300–500 token, overlap ~15% để giữ ngữ cảnh giáp ranh. Với bảng, tôi giữ nguyên cấu trúc hàng (row-aware) và đính kèm tiêu đề cột vào mỗi hàng, vì người dùng hỏi theo hàng chứ không theo ô rời.
Quy tắc tôi luôn nhắc đội: rác đi vào index thì không reranker nào cứu nổi. Chunking là tầng rẻ nhất nhưng quyết định trần chất lượng của cả hệ thống.
Tầng 2 — Embedding: model đơn ngữ là cái bẫy ở thị trường Việt–Nhật
Một câu hỏi tiếng Việt cần truy ra một điều khoản viết bằng tiếng Nhật — đây là tình huống thật, không phải giả định. Embedding model đơn ngữ (hoặc tối ưu cho tiếng Anh) sẽ rớt thẳng ở đây. Tôi chọn embedding model đa ngôn ngữ đặt vi và ja chung một không gian vector, để truy hồi xuyên ngôn ngữ (cross-lingual retrieval) hoạt động.
Một chi tiết hay bị bỏ: thuật ngữ chuyên ngành. Tên sản phẩm bảo hiểm, mã nghiệp vụ, từ viết tắt nội bộ — embedding generic hiểu sai chúng. Tôi giữ một glossary và xử lý các thực thể này ở cả index lẫn query để chúng không bị "dịch nghĩa" sai.
Tầng 3 — Hybrid search: vector giỏi ngữ nghĩa, dở khớp chính xác
Đây là tầng phân biệt RAG demo với RAG production. Vector search tìm theo ý nghĩa — rất mạnh cho câu hỏi diễn giải. Nhưng khi người dùng gõ số hợp đồng HD-2024-887 hay mã điều khoản 第12条, ngữ nghĩa gần như vô dụng; bạn cần khớp từ khóa chính xác.
Giải pháp là chạy song song hai retriever — dense (vector) + sparse (BM25) — rồi hợp nhất bằng Reciprocal Rank Fusion. Vector bắt câu hỏi diễn giải, BM25 bắt mã định danh và thuật ngữ hiếm. Riêng tầng này thường là cú nhảy recall lớn nhất trong cả pipeline.
Tầng 4 — Reranking: tách "đủ liên quan" khỏi "đúng cái cần"
Retriever trả về top-k nhanh nhưng thô. Một cross-encoder reranker đọc lại từng cặp (câu hỏi, chunk) và chấm điểm liên quan thật sự, kéo top-50 thô xuống còn top-5 tinh. Khác biệt: retriever embed câu hỏi và chunk độc lập; reranker nhìn chúng cùng nhau, nên bắt được sắc thái mà cosine similarity bỏ sót.
Cái giá là độ trễ — rerank tốn thời gian. Nên tôi chỉ rerank top-k thô (50), không rerank toàn corpus. Đây là một đánh đổi tôi cân theo từng dự án, giống mọi quyết định kiến trúc khác.
Tầng 5 — Eval: nếu không đo được, bạn không sở hữu nó
Đây là tầng tách người vận hành RAG khỏi người demo RAG. Không có eval, mọi cải tiến chỉ là cảm tính, và bạn không bao giờ biết một thay đổi làm hệ thống tốt lên hay tệ đi.
Tôi dựng một golden set: vài trăm cặp (câu hỏi → tài liệu nguồn đúng → đáp án mong đợi), gồm cả những câu mà đáp án đúng là "không có thông tin". Rồi đo bằng các chỉ số tách bạch trách nhiệm:
- Recall@k — tài liệu đúng có nằm trong top-k truy hồi không? (đo riêng tầng retrieval)
- Faithfulness / Groundedness — câu trả lời có bám sát nguồn đã truy hồi, không bịa thêm? (đo riêng tầng sinh)
- Tỷ lệ "không biết" đúng lúc — khi không có nguồn, hệ thống có chịu nói "không có thông tin" thay vì phỏng đoán không?
Bảng eval: cộng dồn từng kỹ thuật
Đây là hình dạng kết quả tôi nhìn thấy khi bật từng tầng trên cùng một golden set (con số minh họa từ pattern thực chiến, không phải một dự án đơn lẻ):
| Cấu hình | Recall@5 | Faithfulness | "Không biết" đúng lúc |
|---|---|---|---|
| Naive (chunk cố định + chỉ vector) | 68% | 0.74 | 31% |
| + Structure-aware chunking | 79% | 0.81 | 44% |
| + Hybrid search (BM25) | 88% | 0.85 | 61% |
| + Reranker | 93% | 0.91 | 78% |
Điều đáng chú ý không phải con số cuối, mà là đường đi: mỗi tầng đóng một loại lỗi riêng, và bạn chỉ biết tầng nào đáng tiền khi có bảng này. Một đội báo giá RAG mà không nói được sẽ đo bằng gì, thường là đội chưa từng phải chịu trách nhiệm khi hệ thống trả lời sai trong production.
Đọc một bảng eval và phản biện đầu ra của AI thay vì tin tưởng mù quáng — đó chính là kỹ năng Discernment, một trong 4 trụ tôi tóm tắt ở ghi chú khoá AI Fluency.
RAG này KHÔNG phải cái gì — để khỏi mua nhầm
Tôi nói thẳng cho đúng kỳ vọng. Pipeline này tối ưu cho độ chính xác trên tập tài liệu doanh nghiệp (knowledge base, hợp đồng, quy trình nội bộ) ở quy mô SME đến tập đoàn tầm trung. Nó không phải:
- Một nền tảng xử lý hàng tỷ vector real-time — đó là bài toán hạ tầng khác, cần đội data engineering riêng.
- Một lời hứa "0% sai tuyệt đối" — không hệ thống nào hứa được; cái bạn mua là kiểm soát được và đo được sai số.
- Một lý do để bỏ qua chất lượng dữ liệu nguồn — tài liệu nguồn loạn thì kết quả loạn, và đó là việc cần làm trước khi bàn tới model.
Tư duy phân loại đúng bài toán trước khi chọn công cụ, tôi viết kỹ trong bài Tư duy hệ thống trong giải quyết bài toán kinh doanh.
Nếu bạn đang cân nhắc đưa RAG vào một quy trình mà câu trả lời sai có cái giá thật — và muốn làm với người đo được hệ thống của mình chứ không chỉ demo nó — bạn có thể xem thêm năng lực AI Automation, đọc các câu chuyện dự án thực tế, hoặc gửi bài toán hệ thống để cùng trao đổi.
Nguyễn Phúc Nguyên Châu
Delivery Manager / System Architect
14 năm kinh nghiệm kiến trúc và vận hành hệ thống cho thị trường Việt – Nhật
Câu hỏi thường gặp
Chỉ số quan trọng nhất để đánh giá một hệ thống RAG là gì?
Là retrieval recall (Recall@k) và faithfulness/groundedness, không phải "câu trả lời nghe hay". Recall@k đo xem tài liệu đúng có nằm trong top-k truy hồi không; faithfulness đo xem câu trả lời có bám sát nguồn đã truy hồi không. Nếu retrieval sai, mọi thứ phía sau đều sai.
Khi nào cần hybrid search thay vì chỉ dùng vector search?
Khi truy vấn chứa mã định danh chính xác — số hợp đồng, mã điều khoản, mã sản phẩm. Vector search giỏi ngữ nghĩa nhưng dở ở khớp chính xác (exact match); thêm BM25 (sparse) rồi hợp nhất kết quả giúp bắt được cả hai loại truy vấn.
Nên fine-tune model hay xây RAG cho dữ liệu doanh nghiệp?
Trong hầu hết case enterprise, RAG thắng. Dữ liệu doanh nghiệp thay đổi liên tục — cập nhật điều khoản, tài liệu mới — và fine-tune lại mỗi lần thì vừa tốn vừa khó truy nguồn. RAG cập nhật tri thức bằng cách cập nhật index, và luôn trích dẫn được nguồn, vốn là yêu cầu bắt buộc khi cần compliance.
Vector DB nào nên dùng?
Câu trả lời đúng là "tùy quy mô", không phải "cái nào hot nhất". Ở quy mô SME, một Postgres với pgvector thường là đủ và đơn giản để vận hành. Khi số lượng vector và yêu cầu latency tăng, một vector DB chuyên dụng (Qdrant, Milvus...) mới đáng cái chi phí vận hành thêm. Chọn vector DB trước khi biết quy mô là đặt cày trước trâu.
Phần đắt nhất khi xây RAG thật nằm ở đâu?
Không phải model hay vector DB — mà ở **chuẩn hóa dữ liệu nguồn** (tầng 1) và **dựng bộ eval** (tầng 5). Đây là phần "không sexy" nhưng quyết định hệ thống sống hay chết. Đội nào báo giá chỉ tính tiền gọi API model thường là đội chưa từng vận hành RAG thật trong môi trường mà sai số có cái giá thật.